It’s not often I find a video changes how I think about my future but that’s what happened with this one.


It’s not often I find a video changes how I think about my future but that’s what happened with this one.
The Artist and the Scientist
by Marc Cohen

In a revelation that will surprise no one who knows me, I was a very enthusiastic child. When I found something I liked, everyone had to hear about it. Come to think of it, I’m still the same way now, hence “One Great Thing”.
When you said “take me off this thread,” you denied who I am.
When you said “you must have dementia,” you denied who I am.
When you said “we can’t talk about that,” you denied who I am.

I’m convinced you could spend the rest of your life watching YouTube videos and barely scratch the surface of fascinating educational content (not that I would recommend spending your life that way). The video featured in today’s post is one such hidden gem, on the mysterious origin of several common English words.

I know many Jewish people who feel very strongly about Palestinians, yet have never met one. Think about that. If this describes you, it means you’re holding judgments about 15 million human beings without a single personal encounter.

Check out this beautifully crafted, inspiring, award-winning short film. It tells the story of Madeleine, a spirited 106 year old woman who reluctantly travels to the beach with her young filmmaker friend.

Have you ever imagined what it might be like to be blind? I don’t mean to lose your sight, but rather to never have had it in the first place.

I just watched a documentary that touched my heart and outraged me at the same time.

I’m down with any initiative that encourages book people to spend more time with other book people.

How important do you think social interactions are? Are they just nice to have or a critical ingredient for a healthy and happy life?

Two weeks ago, in Writing as Therapy, I wrote about how much I’ve enjoyed and profited from journaling for ten minutes every morning. Continuing that theme, here’s a related article, which summarizes some scientific findings on the surprisingly powerful mental health benefits of this daily practice.

If you’re a fan of classic rock, I have a video for you. In this beautiful black and white footage recorded in Denmark in 1969, Led Zeppelin performs a haunting arrangement of Babe I’m Gonna Leave You from their first album.

I’ve been journaling every morning for the last several weeks and have found it to be a great way to organize my thoughts and process some of the many loose threads in my head.

Today’s One Great Thing is a neat puzzle that falls into one of my favorite categories: on first hearing this your reaction will likely be “that’s impossible”. But, of course, there is a solution. You just have to think about it in the right way.

As a child, I was a world class daydreamer. By which I mean that my mind was constantly wandering, which was often commented upon with some concern by my teachers.

The first time you see Puddles Pity Party you might be tempted to dismiss him based on appearances. How do you take seriously a gigantic (6'8”) man dressed in a clown suit, who refuses to speak?

As a loud and proud Jewish critic of Israel’s apartheid regime, I’m sometimes asked this question: why don’t you spend more energy calling for the release of the hostages? In this brief article, I’ll share my answer to that question.

One of the best things about living in London is the pervasive and efficient train network, affectionately known as the Tube. You can get just about anywhere in this sprawling metropolis by train and it’s my favorite way to travel around the city.

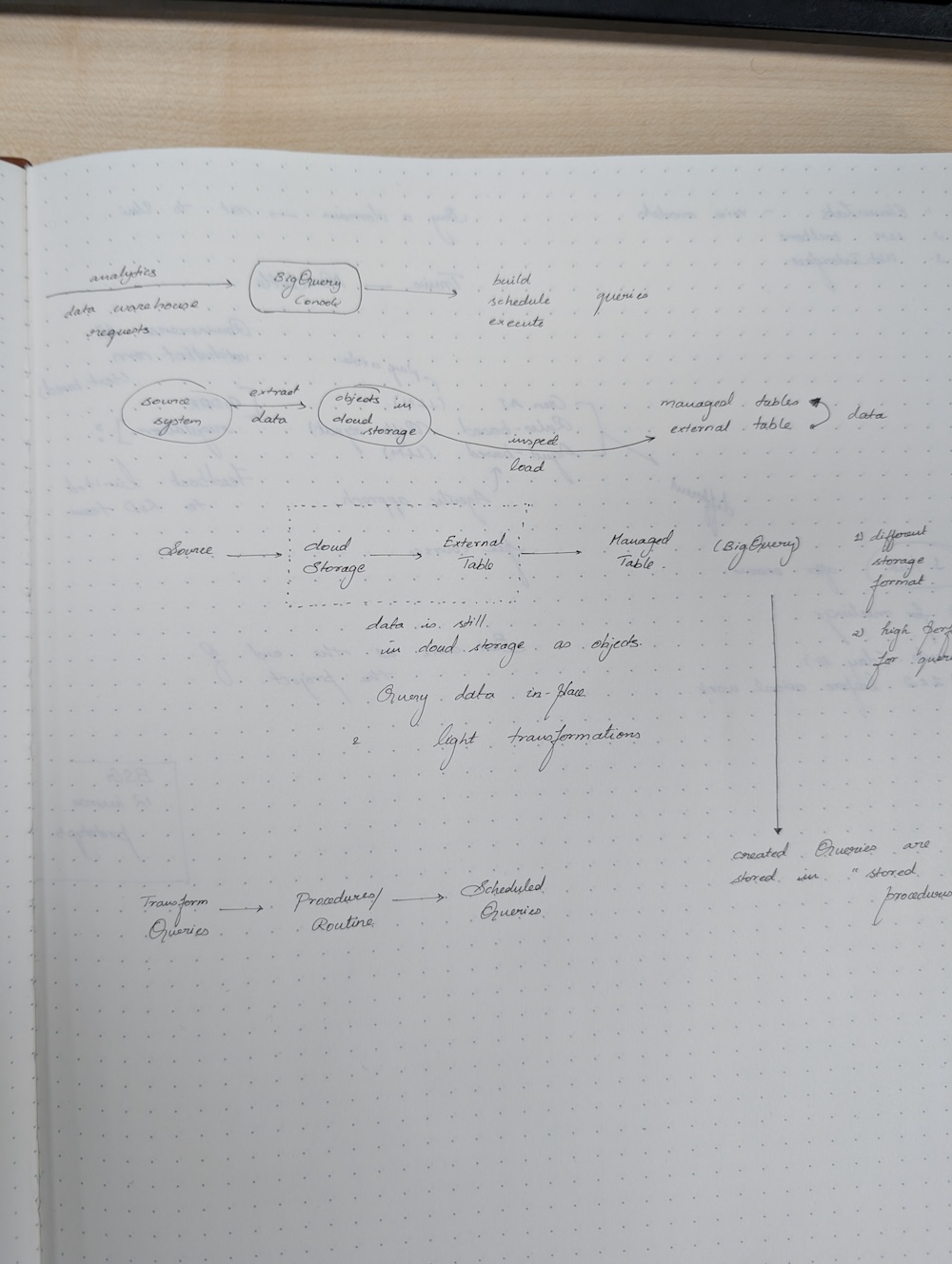
I’ve been teaching a class at the University of Surrey in South London. During a recent lab session, a friendly student named Satish Ranganathan Mohan approached me with a question and I noticed the most exquisite hand-written diagram and calligraphy I’ve ever seen.
Whether you’re a long time fan of Jeopardy! or not, you have to appreciate Harvey Silikovitz, who, despite having Parkinson’s Disease, won the notoriously challenging quiz show last Monday after a 24 year journey.

Today’s one great thing is a short article about a powerful life hack everyone should know about.

Have you ever done that thing where you fall asleep on a train and miss your stop? If you do that in Tokyo, you might just end up at a “Station of Despair”.
If, like me, you’re a Beatles fan and you enjoy a good amateur detective story, this article will be right up your alley.

I’m always pondering what it means to live a good life, a meaningful life, a rewarding life.

I recently had a conversation with someone close to me about religion. They were asserting that the Tibetan belief in a reincarnated soul is not a form of religious indoctrination. I disagreed but the point of this article is not the substance of that discussion but rather my reaction to the conversation.

Our memories are what make us who we are. They are the building blocks of our identity. I feel sad when I think about how many little details of my life I can’t remember.

You know that feeling when you have something important to do and you just can’t seem to get off the starting block? It’s not necessarily an unpleasant task, and once you get working on it, it’ll be fine. It’s just that the energy required to make the transition from idle to active can feel overwhelming at times. In this article I’m sharing the best solution I’ve found to this problem.

I recently noticed that I’ve been reading fewer books lately. I think it’s because I’ve been spending a disproportionate share of my time reading blogs, news sites, a certain social media feed, and other less substantial content. Then I read Blake Butler’s Maximizing Time for Reading, which put everything into focus for me.

You’ve heard this song, undoubtedly one of the greatest in Rock and Roll history, a million times. But this particular version is special.
