
What’s bigger than Wikipedia? Spoiler: Wikipedia page views. This is the first of a two part series in which we’ll explore how to build a data engineering solution to process all 10TB of published wikipedia pageviews and entity data.
In Part 2 of this series we’ll cover some of the fun things we can do once we have our data pipeline running: interesting queries and data visualizations and a Data Studio dashboard you can try yourself.
Introduction
I often give talks to students and I like to ask if anyone knows what’s represented in the cover photo of this article. I find it amusing that many aren’t sure what they’re looking at, so I inform them how, when I was their age, that was my Wikipedia.
Because it’s a centralized web resource, Wikpedia has an interesting property that the encyclopedias of my childhood could never match: it can see every page access. The Wikimedia Foundation, which operates and maintains Wikipedia, provides detailed access logs on an hourly basis. This information contains an entry for every view of every article, anywhere in the world, in any language.
The relative popularity of Wikipedia pages provides an interesting glimpse into what we, collectively, find interesting. This data is fun to work with for another reason: it’s Big - there’s more data in one year’s access logs than in all the articles combined in every supported language! Wikipedia logs on the order of 250MB of access data every hour. That’s roughly 30*24*250 = 180,000MB = 180GB per month, or 2.16TB per year. The Wikimedia foundation has been publishing this data since 2015 so the entire dataset is now over 10TB.
Page views aren’t enough
The kind of queries I’m interested in asking are of this form: what was the most popular wikipedia page in category X over timeframe Y (and how did that popularity change over time)? For example, it would be interesting to see whether the major Democratic presidential candidates’ Wikipedia page views correlate with their success in polls and primaries.
But think about it – how would you go about constructing a query of all Democratic presidential candidates? The simplest approach would be to simply enumerate the known candidates. But that immediately ties our query to the current state of the world. Ideally, our queries should automatically adjust their scope to incorporate the current set of pages of interest.
To automatically find categories of pages of interest, we need metadata, which is information about wikipedia entities.
Wikidata to the rescue
It turns out, the Wikimedia foundation provides just such a collection of metadata. It’s called the Wikimedia Entity Database (wikidata for short). You can think of Wikidata as information about the entities in Wikipedia. It could be a song, a country, a TV show, a politician, a University, or anything else you might like to classify. Here’s an excerpt of the Wikidata entry for “Barack Obama”:
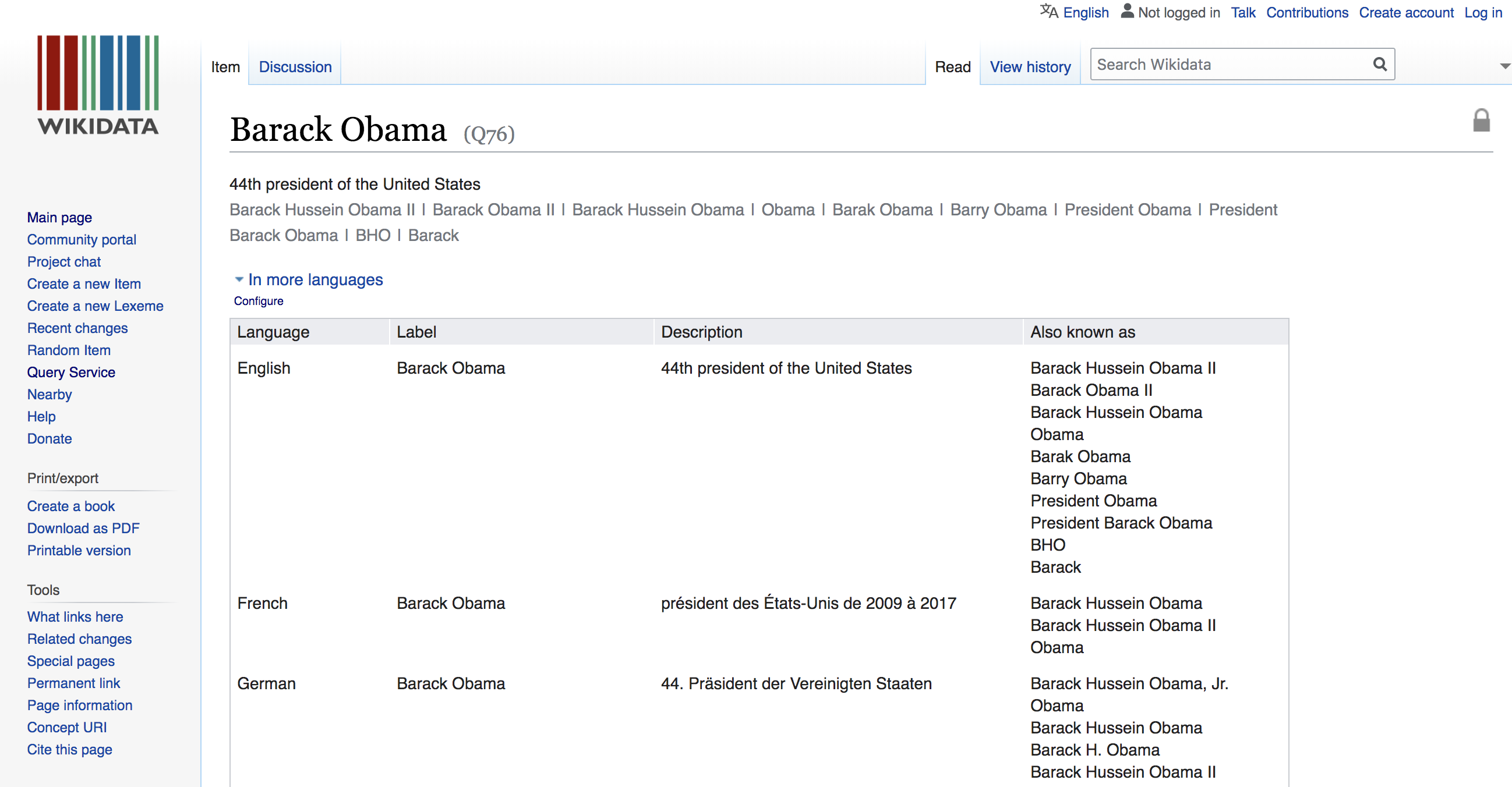
Armed with the page views and the wikidata, we can run powerful categorical queries. But there’s one catch: the Wikidata is huge: 400GB compressed and nearly 1TB uncompressed. So we’ll need to handle it with care.
What problem are we trying to solve?
This is starting to look bigger than an afternoon job. Whenever a project starts to feel a bit complicated, I like to make a list of requirements to make sure I understand the problem I’m trying to solve. Here’s a diagram summarizing the data I’ve just discussed followed by a short list of requirements for my solution:

- Page view data files are published hourly. We’ll gather them within an hour of release.
- Hourly page view files are typically on the order of 50MB uncompressed. That’s small enough that we can process them using a serverless method like Cloud Run, which will save us a lot of administrative hassle.
- Wikidata is released every three days. We’ll gather the latest copy within 24 hours of its release.
- Wikidata requires a large (1TB) decompression. It’s too big a job for a serverless mechanism so we’ll allocate a dynamic virtual machine, which we can dedicate to this task for as long as we need it.
- We should store records of all the data we’ve downloaded (file names and sizes) so that we can determine what we’re missing at any given moment.
- We should load all gathered data, both page views and wikidata, into BigQuery to facilitate fast, dynamic queries via standard SQL, and to make this data publicly available.
- All of the above must be automated so that the latest data is always available and we never have to rely on manual processes.
The naive approach (and why it’s not the best plan)
What’s the simplest and most obvious way to do this? Download the data to your laptop using curl or wget, and upload the files from your local hard drive to the Cloud, where you can use modern cloud computing tools to extract meaningful insights and data visualizations.
What could possibly go wrong? Well, a lot…
- Space: You may not have enough free space available to store the downloaded files.
- Time: This is probably going to take a while because it’s using spare CPU cycles on a single laptop.
- Efficiency: You’re transferring every byte twice - once from the source to your laptop and once from your laptop to the cloud.
- Comfort: Your personal device is now dedicated to an onerous background task - hope you don’t mind that whirring fan for the next eight hours!
- Resilience: What happens when your laptop goes to sleep or loses connectivity or reboots in the middle of a multi-hour transfer?
- Automation: This is a manual task but we really want it be 100% automated to minimize errors and ensure it always runs, regularly and reliably, with audit logs.
In short, this is not what we’d call a well engineered process, so let’s fix that…
Can we script it?
Sometimes low tech is the best choice for getting started. This job is mostly about moving files around, comparing what we’ve already acquired with what’s available on the web, and taking appropriate actions. Most of those operations already exist in Linux commands, like wget, gsutil, awk, comp, etc. Consider the following shell script (pageviews.sh), which takes care of gathering all the latest page view data:
Click here to expand code
|
|
This script can be called with any of the following time window arguments: day, month, year, or all. It audits our existing data over the requested time window and ingests any missing files. This script is idempotent by design – you can call it repeatedly and it will always try to make our copy of the data match the publicly available data.
The last step in the script calls a sub-script (update.sh) which parses the newly acquired data and loads it into the appropriate BigQuery table. It looks like this:
Click here to expand code
|
|
Wikidata decompression - We’re gonna need a bigger boat
That takes care of the pageviews, but what about the wikidata? Here’s a script called entities.sh, which takes care of the entity data. Structurally, it’s similar to the pageviews.sh script, except that instead of acquiring the data, it simply prints the file name it would like to acquire. The reason we do this is because we’re not going to actually gather the entity data in this script – it’s too big a job, involving a large download, a massive decompression, and a huge upload. Instead, we’ll use this script to drive the Storage Transfer service.
Click here to expand code
|
|
Let’s productionize this thing
So far, we have a bunch of shell scripts but we need to run those scripts automatically, in the cloud, at the right times. Cloud Run gives us that capability.
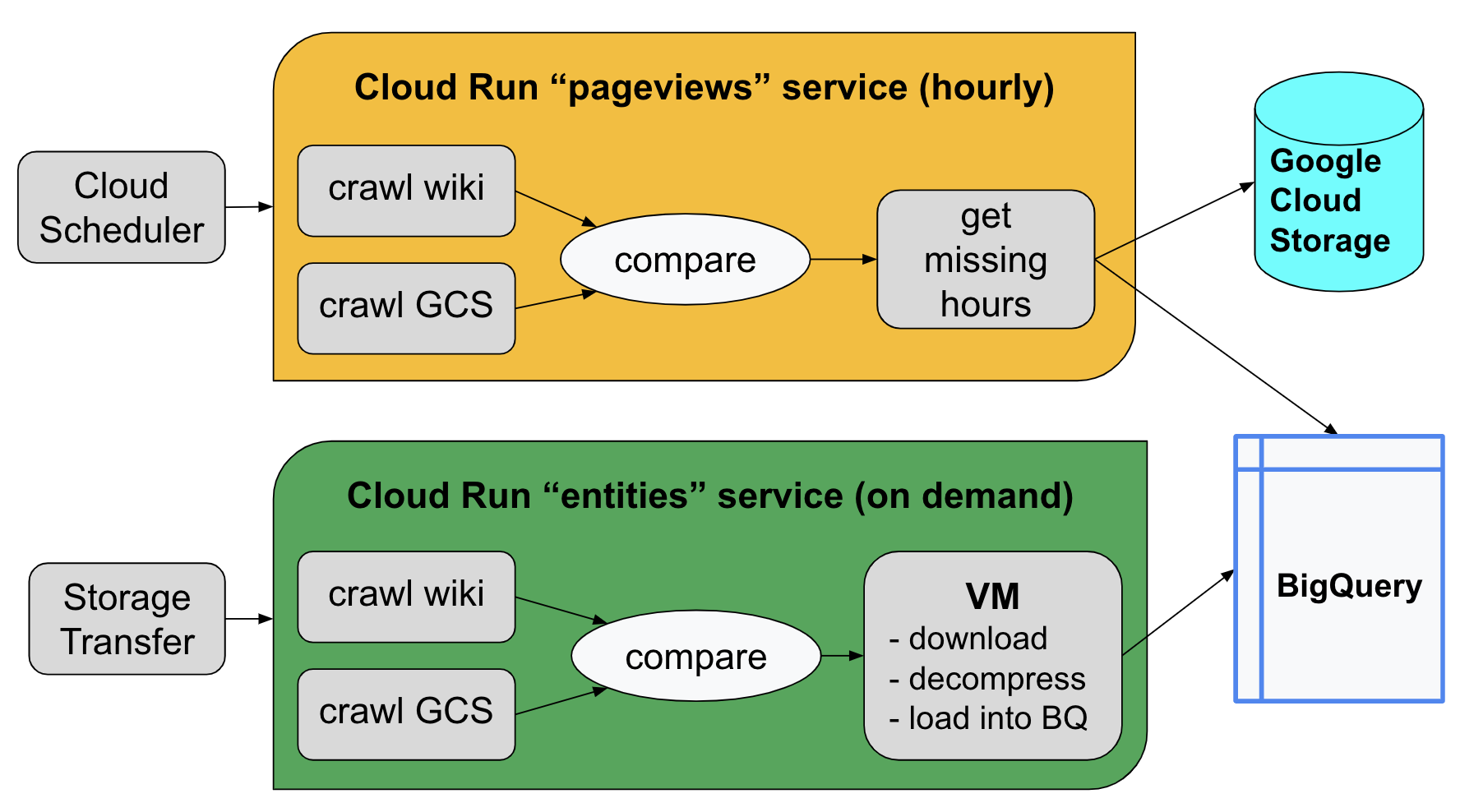
We wrap the pageviews.sh script in a Cloud Run job that runs once per hour. Any new files are automatically downloaded to Cloud Storage, parsed, and loaded into a BigQuery table.
The entities.sh script is used to drive a Storage Transfer job. Once a day it looks for new wikidata on the web and, if found, it downloads the file to Cloud Storage. Once the new file is stored in GCS, it triggers a cloud run job called load.sh, which looks like this:
Click here to expand code
|
|
This script creates a high end (m1-ultramem-80) virtual machine to process the new wikidata file. The details of the processing are specified in the startup script, startup.sh, which consists of the following steps:
- download compressed entity data from cloud storage using gsutil
- parallel uncompress entity data using lbunzip2
- upload uncompressed file back to Cloud Storage using gsutil
- load uncompressed json from Cloud Storage to BigQuery using bq command
Conclusion
We now have a robust, reliable, and mostly serverless data processing pipeline to gather new page views every hour and replace the entity data within 24 hours of its release. In part 2 of this series, we’ll have some fun exploring this data, both with SQL queries and Data Studio visualizations.
Resources and Acknowledgements
- Part 2 of this series
- All of the code described in this article can be found at github.com/marcacohen/wikidata.
- Many thanks to Felipe Hoffa. Several of the queries and data management techniques in this article were derived from Felipe’s excellent articles on partitioning and lazy loading, and clustering.
- Shane Glass provided invaluable support helping me add this data to the wonderful Google Cloud Public Datasets collection.