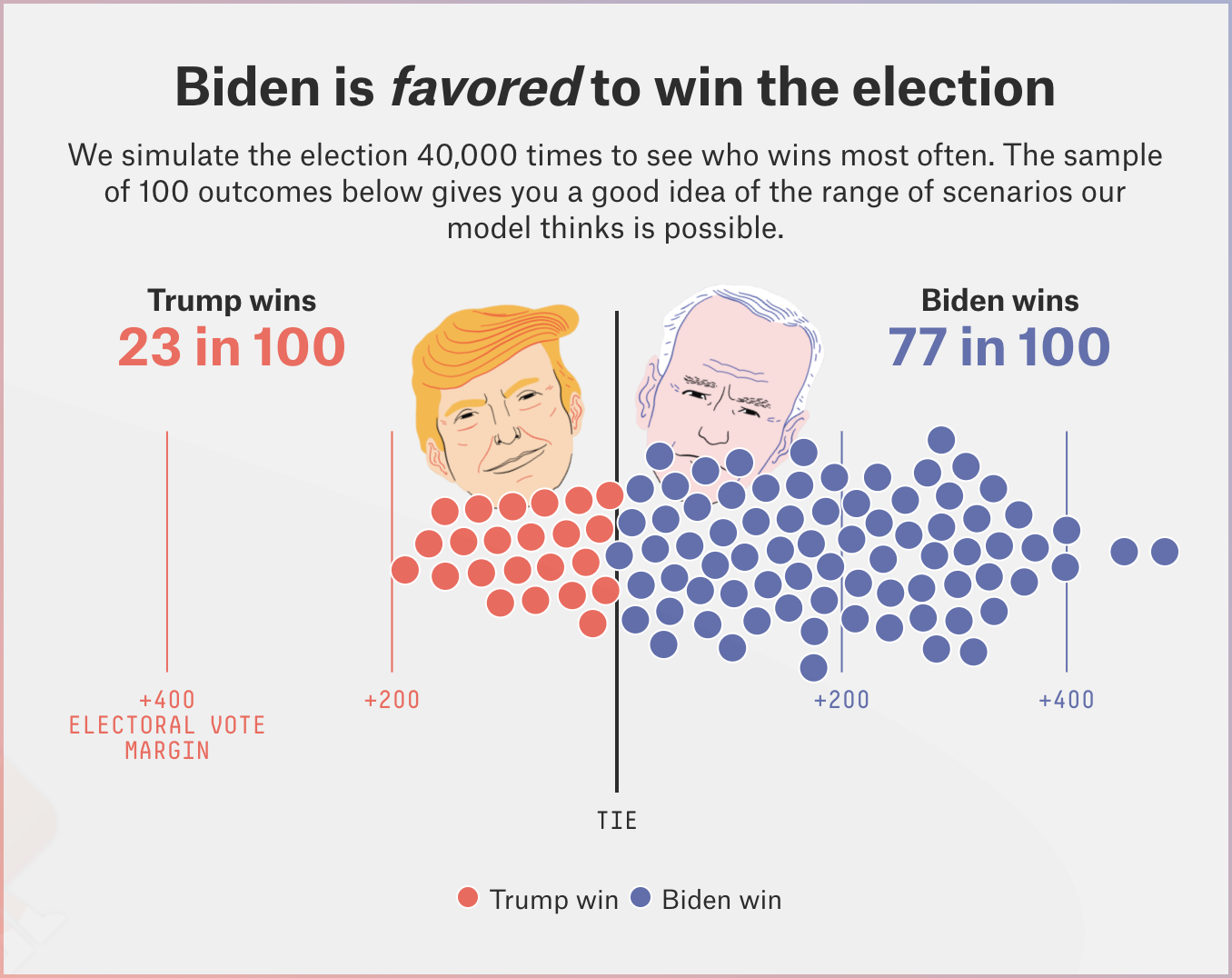
Jupyter Notebooks are awesome but there are so many. Just at Google we have Colab, Kaggle Notebooks, and Cloud AI Platform Notebooks. So which should you use? The answer is “it depends”. This session will summarize your options and try to help you choose the best notebook for your needs.